本周,两家美国人工智能实验室发布了开源模型,但它们采用了完全不同的策略来应对同一个挑战:如何在公共人工智能系统领域与中国的主导地位竞争。

Deep Cogito 发布了 Cogito v2.1,这是一个拥有 6710 亿个参数的庞大模型,其创始人 Drishan Arora 称之为“美国公司最好的开放权重 LLM”。
艾伦人工智能研究所反驳道:“别急。”奥尔莫 3Olmo 3 被誉为“最佳完全开源的基础模型”,并拥有完全的透明度,包括其训练数据和代码。
具有讽刺意味的是,Deep Cognito 的旗舰机型正是建立在……之上的。中国基金会Arora 在 X 上承认,Cogito v2.1“从 2024 年 11 月起,基于开源许可的 Deepseek 基础模型分叉而来”。
这引发了一些批评,甚至引发了关于微调中国模型是否算作美国人工智能进步的争论,或者这是否仅仅证明了美国实验室落后了多少。
无论如何,Cogito 相对于 DeepSeek 的效率提升是真实存在的。
Deep Cognito 声称 Cogito v2.1 生成的推理链比 DeepSeek R1 短 60%,同时保持了具有竞争力的性能。
Arora 称之为“迭代提炼和放大”——通过自我改进循环来训练模型,使其发展出更好的直觉——这家初创公司仅用了 75 天就利用 RunPod 和 Nebius 的基础设施训练出了自己的模型。
如果基准测试结果属实,这将是目前由美国团队维护的最强大的开源LLM。
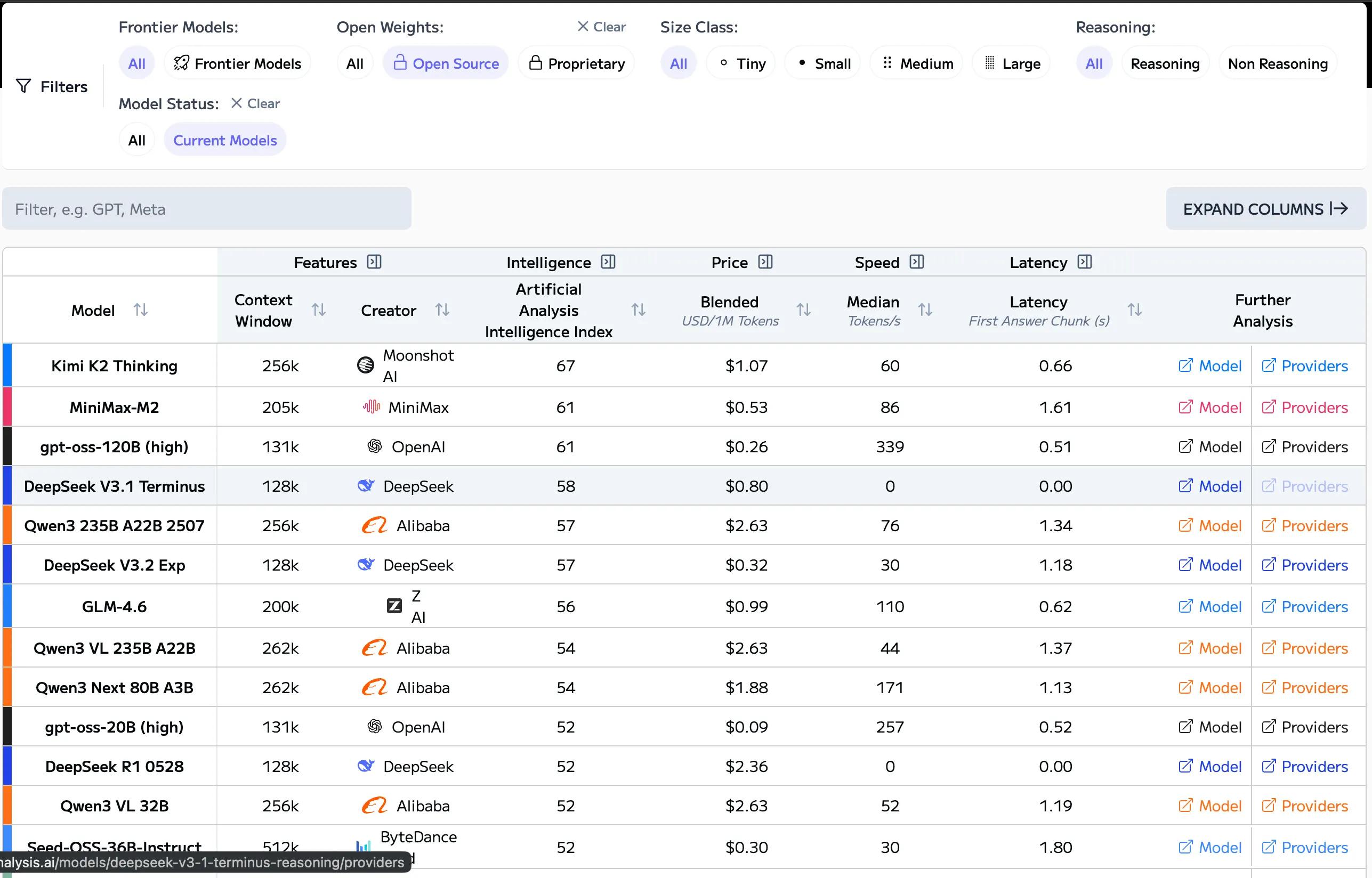
为什么这很重要到目前为止,中国在开源人工智能领域一直处于领先地位,美国公司为了保持竞争力,越来越依赖中国的基础模型——无论是悄悄地还是公开地。
这种动态存在风险。如果中国实验室成为全球开放人工智能的默认平台,美国初创企业将失去技术独立性、议价能力以及制定行业标准的能力。
开放权重人工智能决定谁控制着下游所有产品所依赖的原始模型。
目前,中国开源模型(DeepSeek、Qwen、Kimi、MiniMax)主导全球采用因为它们价格低廉、速度快、效率高,而且不断更新。.